Sampling from the posterior
Contents
![]()
3.1. Sampling from the posterior¶
In this example we re-create the planar SLAM example, and then explore three techniques to obtain samples from the posterior:
sampling from the Gaussian Laplace-approximation provided by Marginals;
using the Gaussian as a proposal density for importance sampling;
Metropolis sampling with the tangent-space Gaussian as proposal density.
The Laplace approximation is simply taking the inverse of the Hessian at convergence as the covariance matrix of a Gaussian density around the MAP estimate. The Marginals class provides efficient methods to calculate any joint marginal of this density. However, especially when using nonlinear measurements such as bearing or bearing-range measurements it is important to realize just how much of an approximation this is, as will be illustrated below.
%pip -q install gtbook # also installs latest gtsam pre-release
Note: you may need to restart the kernel to use updated packages.
import math
from math import pi, sqrt
import matplotlib.pyplot as plt
import numpy as np
from collections import defaultdict
import plotly.express as px
try:
import google.colab
except:
import plotly.io as pio
pio.renderers.default = "png"
import gtsam
import gtsam.utils.plot as gtsam_plot
from gtbook.driving import planar_example, marginals_figure
from gtbook.display import show
from gtbook.gaussian import sample_bayes_net
from gtsam import Point2, Pose2, Rot2, noiseModel
3.1.1. Setting up a non-linear SLAM Example¶
Below we re-create a similar factor graph as in PlanarSLAMExample:
graph, truth, keys = planar_example()
x1, x2, x3, l1, l2 = keys
show(graph, truth, binary_edges=True)

As always, we can calculate and plot covariance ellipses which show the Laplace approximation graphically.
marginals = gtsam.Marginals(graph, truth)
marginals_figure(truth, marginals, keys)
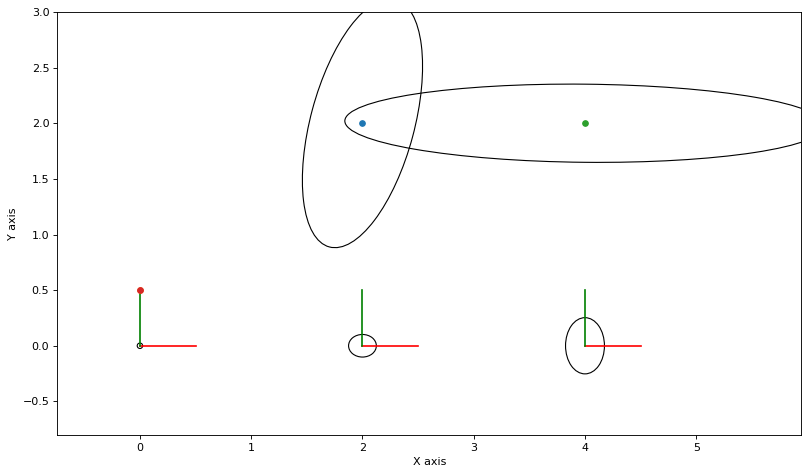
3.1.2. The Laplace Approximation on the Manifold¶
To sample from the Laplace approximation we will use the corresponding Bayes Net, as it provides an efficient ancestral sampler. When we linearize at the ground truth and subsequently eliminate the resulting Gaussian factor graph, we obtain a Gaussian Bayes net, as shown below.
bayes_net = graph.linearize(truth).eliminateSequential()
show(bayes_net)

The gtbook.gaussian.sample_bayes_net, which implements efficient ancestral sampling, yields samples in the tangent space, which we then need to upgrade to the non-linear manifold:
def vector_values(tangent_samples:dict, s:int):
"""Create VectorValues from sample dictionary."""
vv = gtsam.VectorValues()
for key in tangent_samples.keys():
vv.insert(key, tangent_samples[key][:, s])
return vv
def perturb(tangent_samples:dict, values:gtsam.Values, s:int):
"""Perturb manifold values by tangent_samples[s]."""
return values.retract(vector_values(tangent_samples, s))
N = 5000
tangent_samples = sample_bayes_net(bayes_net, N)
manifold_samples = [perturb(tangent_samples, truth, s) for s in range(N)]
# Calculate and plot samples
marginals_figure(truth, marginals, keys)
def plot_sample(manifold_sample, alpha=0.1):
point = np.empty((2, 5))
for i in [1, 2, 3]:
point[:,i-1] = manifold_sample.atPose2(gtsam.symbol('x', i)).translation()
for j in [1, 2]:
point[:,j+2] = manifold_sample.atPoint2(gtsam.symbol('l', j))
plt.plot(point[0], point[1], 'k.', markersize=5, alpha=alpha)
for manifold_sample in manifold_samples:
plot_sample(manifold_sample)
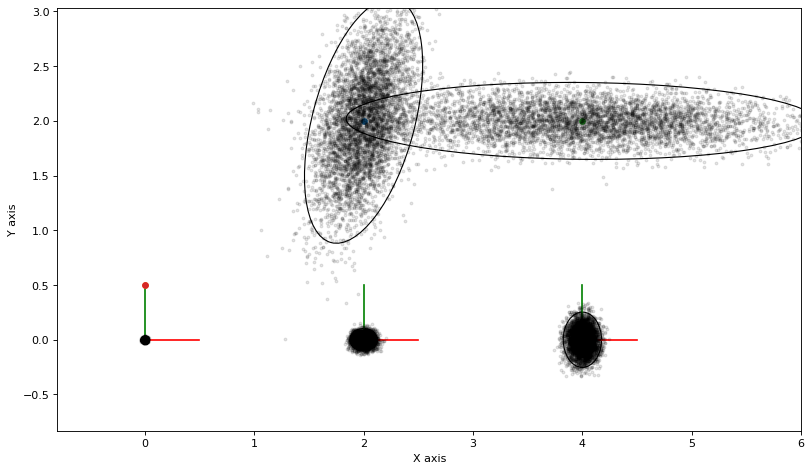
3.1.3. Importance Sampling¶
Below we use the same samples, but now use them to calculate importance weights. We then plot the same samples as above but with an opacity proportional to the importance weight. This is unfortunately slow with matplotlib.
marginals_figure(truth, marginals, keys)
def weight(s, manifold_sample):
# calculate error
error = graph.error(manifold_sample)
# calculate importance weight
vv = gtsam.VectorValues()
for key in tangent_samples.keys():
vv.insert(key, tangent_samples[key][:, s])
q = bayes_net.error(vv)
return math.exp(q - error)
weights = np.array([weight(s, manifold_sample)
for s, manifold_sample in enumerate(manifold_samples)])
weights /= np.max(weights)
for s, manifold_sample in enumerate(manifold_samples):
plot_sample(manifold_sample, alpha=weights[s])
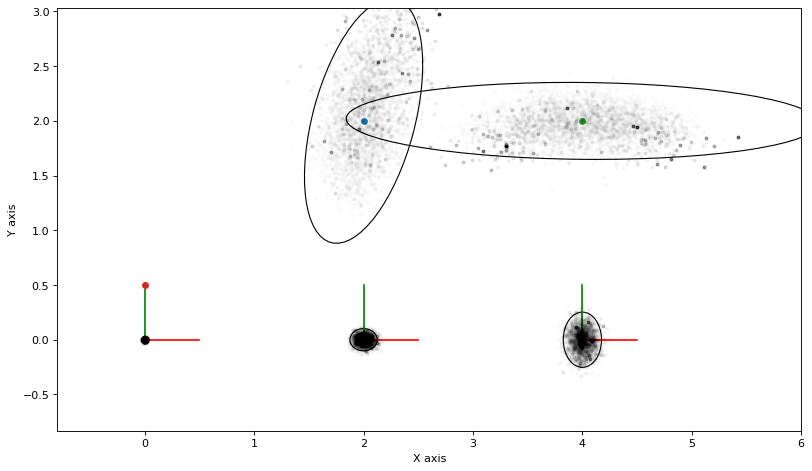
Note how the landmark densities are now definitely non-Gaussian: landmark \(l_1\) is bearing only, and there is a “cone-like” extension of the density towards the top of the figure. Landmark \(l_2\) is shaped like an arc, because of the uncertain bearing measurement coupled with a fairly good range measurement.
The importance weight is calculated using the probability of the entire graph, for each perturbed manifold sample. Because the entire state is high-dimensional (in this case 13 dimensional) the variance of importance sampling will be high. You can actually see this in the plot, as there are a few high weight samples that dominate. Any expectation derived from these weighted samples will be rather poor in quality.
3.1.4. Metropolis Sampling¶
A better approach is to use Markov Chain Monte Carlo (MCMC) sampling. As it happens, we can easily use the Bayes net sampler we created above to set up a Metropolis sampler:
Start with an initial estimate \(x\)
loop \(N\) times:
propose \(x' \sim q(x'|x)\) where we use the Bayes net density centered at \(x\)
calculate the acceptance ratio \(a = p(x')/p(x)\)
accept \(x'\) as a (correlated) sample from \(p(x)\) with probability \(\min(1,a)\).
To implement the proposal density \(q(x)\) we use the Gaussian density on the tangent space created at the ground truth, but use the current sample to generate a sample on the manifold. While we could create a new Laplace approximation for each new sample \(x\) this would be expensive, and it is in fact not needed, as the proposal density is arbitrary. The intuition here is that the Laplace approximation is still much better than, say, an isotropic Gaussian as long as we are not too far the MAP solution.
marginals_figure(truth, marginals, keys)
N = 20000
nr_accepted = 0
tangent_proposals = sample_bayes_net(bayes_net, N)
def accept(log_a):
"""calculate acceptance, with some care to avoid overflow."""
if log_a >= 0:
return True
if log_a < -10:
return False
return np.random.uniform() < math.exp(log_a)
# Start with an initial estimate x
x = perturb(tangent_proposals, truth, 0)
error_x = graph.error(x)
# loop N times:
for s in range(1, N):
# propose p
p = perturb(tangent_proposals, x, s)
# Draw marginal sample if we accept:
error_p = graph.error(p)
log_a = error_x - error_p
if accept(log_a):
x = p
nr_accepted += 1
error_x = error_p
plot_sample(x, alpha=0.1)
print(f"nr_accepted={nr_accepted}")
nr_accepted=1253
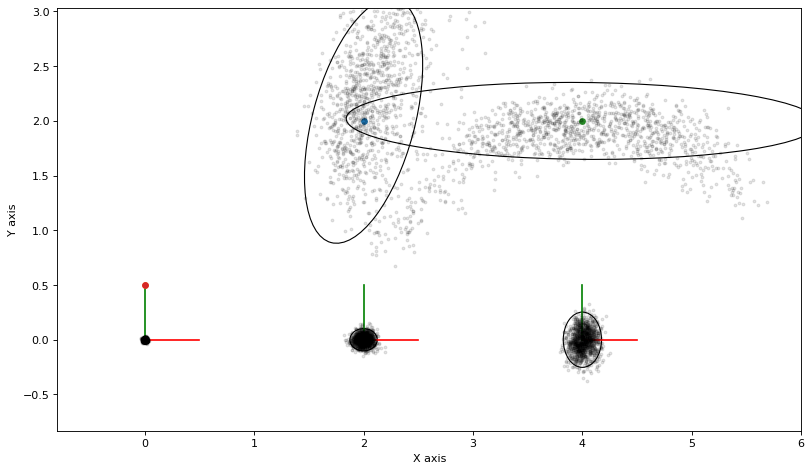
It is clear that MCMC is able to capture the shape of the posterior very nicely. The downside is that the samples were generated from a Markov chain and are correlated, so you have to be careful when using it.
3.1.5. Local MCMC Proposals¶
Another MCMC variant that is conceptually simpler could work directly on the factor graph is Gibbs sampling. The algorithm iterates over all variables \(x_j\) in turn and generates a new sample \(x\), automatically accepted, by sampling from \(P(x_j|X_j)\), where \(X_j\) is the separator of variable \(x_j\). Unfortunately, calculating this conditional probability exactly is again a hard problem, and sampling from it can be expensive as well.
However, the idea of creating picking a variable and creating a proposal that only involves one of the variables rather than all of the variables is potentially more performant because of two reasons:
the acceptance ratio can be calculated using local factors only;
because we only perturb one variable, we are more likely to accept.
We implement this idea below. First, we calculate all local factor graphs as a dict (TODO: gtsam.VariableIndex should behave as a dict):
markov_blankets = defaultdict(gtsam.NonlinearFactorGraph)
for i in range(graph.size()):
factor = graph.at(i)
for j in factor.keys():
markov_blankets[j].add(factor)
for j, local in markov_blankets.items():
print(f"{gtsam.DefaultKeyFormatter(j)}: {local.size()} factors")
x1: 3 factors
x2: 3 factors
x3: 2 factors
l1: 2 factors
l2: 1 factors
Then we run Metropolis sampler where the proposal randomly picks a variable to perturb, and then uses the local factor graph to calculate the acceptance ratio.
marginals_figure(truth, marginals, keys)
nr_accepted = 0
def accept(log_a):
"""calculate acceptance, with some care to avoid overflow."""
if log_a >= 0:
return True
if log_a < -10:
return False
return np.random.uniform() < math.exp(log_a)
def plot_sample(manifold_sample, alpha=0.1):
points = np.empty((2, 5))
for i in [1, 2, 3]:
points[:,i-1] = manifold_sample.atPose2(gtsam.symbol('x', i)).translation()
for j in [1, 2]:
points[:,j+2] = manifold_sample.atPoint2(gtsam.symbol('l', j))
plt.plot(points[0], points[1], 'k.', markersize=5, alpha=alpha)
return points
marginals_figure(truth, marginals, keys)
N = 50000
stats = []
nr_accepted = 0
gbn = graph.linearize(truth).eliminateSequential()
tangent_proposals = sample_bayes_net(gbn, N)
# Start with an initial estimate x
x = gtsam.Values(truth)
for s in range(N):
# choose a variable to perturb
j = keys[np.random.choice(5)]
vvj = gtsam.VectorValues()
vvj.insert(j, tangent_proposals[j][:, s])
p = x.retract(vvj)
# calculate local acceptance ratio
log_a = markov_blankets[j].error(x) - markov_blankets[j].error(p)
if accept(log_a):
nr_accepted += 1
x = p
plot_sample(x, alpha=0.01)
print(f"nr_accepted={nr_accepted}")
nr_accepted=14778
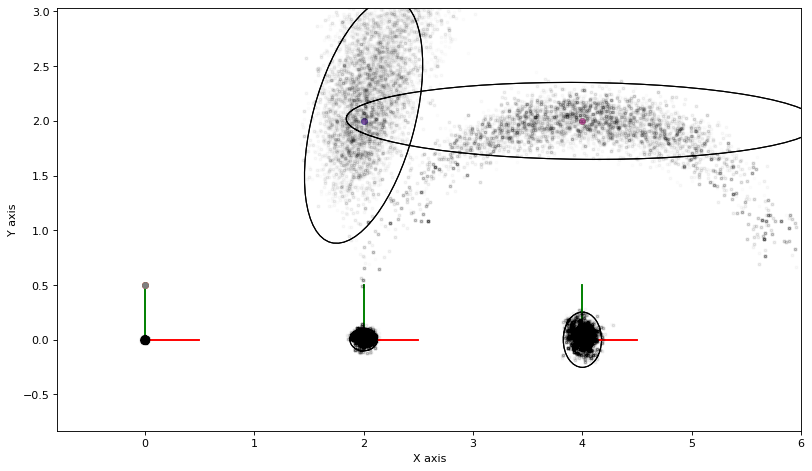
3.1.6. Computing Expectations¶
One way to use the MCMC samples is to approximate expected values under the posterior. In the example code we calculate the Monte Carlo expectations of \(l_1\) and \(l_2\), and they indeed agree with the MAP estimate. However, calculating the distance between those two landmarks is a nonlinear operation, and its Monte Carlo estimate deviates significantly from the estimate calculated at the ground truth solution. We also plot the histogram for the distance to show this more clearly.
marginals_figure(truth, marginals, keys)
# Start with an initial estimate x
x = gtsam.Values(truth)
error_x = graph.error(x)
l1_sample, l2_sample = x.atPoint2(l1), x.atPoint2(l2)
d12_sample = np.linalg.norm(l2_sample - l1_sample)
# Set up data structures to calculate posterior expectations
sums = {}
d12_samples = [d12_sample]
sums = {1:l1_sample, 2:l2_sample, 3:d12_sample}
num_accepted = 1
# loop N times:
for s in range(1, N):
# propose p
p = perturb(tangent_proposals, x, s)
# Draw marginal sample if we accept:
error_p = graph.error(p)
log_a = error_x - error_p
if accept(log_a):
x = p
error_x = error_p
l1_sample, l2_sample = x.atPoint2(l1), x.atPoint2(l2)
d12_sample = np.linalg.norm(l2_sample - l1_sample)
# Update data structure
d12_samples.append(d12_sample)
sums[1] += l1_sample
sums[2] += l2_sample
sums[3] += d12_sample
num_accepted += 1
for key in [1,2]:
point = sums[key] / num_accepted
plt.plot(point[0], point[1], 'rx', markersize=10)
print(f"MAP estimate for d12 = {np.linalg.norm(truth.atPoint2(l2)-truth.atPoint2(l1))}")
print(f"MCMC estimate for d12 = {np.linalg.norm((sums[3])/num_accepted)}")
MAP estimate for d12 = 2.0
MCMC estimate for d12 = 2.0868967367963873
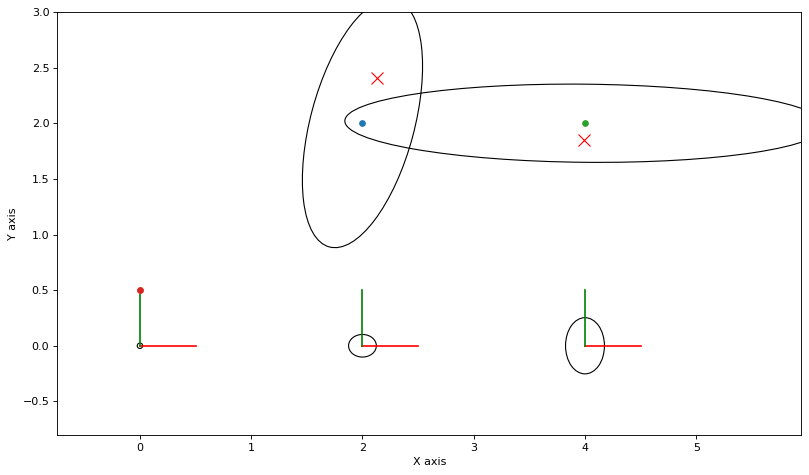
We see that the Monte Carlo expectations for \(l_1\) and \(l_2\) do not agree with a MAP estimate, which is completely expected: the mean and mode of a density typically do not coincide. In addition, the Monte Carlo for their distance also does not agree. We plot the histogram of distance samples below, which is clearly non-Gaussian:
print(f"Histogram for {len(d12_samples)} |l2-l1| samples")
px.histogram(d12_samples)
Histogram for 3435 |l2-l1| samples
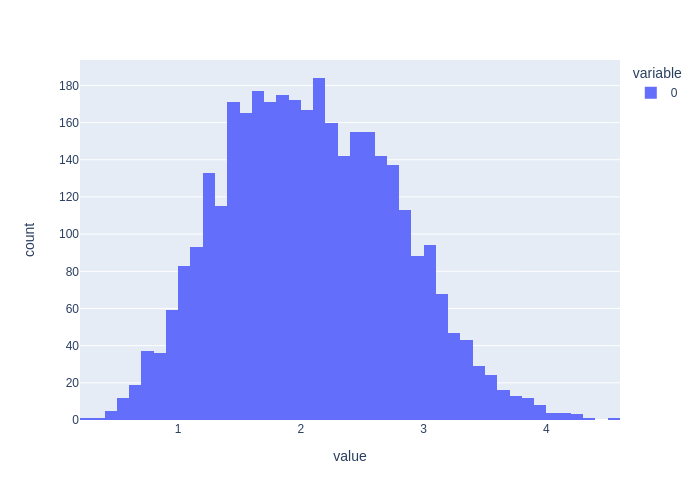
Finally, note that the correct MC expectation differs from taking the distance between the MCMC estimates, as distance is nonlinear:
print(f"Incorrect estimate for d12 = {np.linalg.norm((sums[2]-sums[1])/num_accepted)}")
Incorrect estimate for d12 = 1.9437117384738316
Finally, please know that all of these are estimates, and have considerable variance. You can re-run the above code a few times to get an idea of the variance.